 Packet Classification Algorithms —— HyperSplitHyperSplit
Packet Classification Algorithms —— HyperSplitHyperSplit
作者:Yaxuan Qi, Lianghong Xu and Baohua Yang. Yibo Xue and Jun Li
时间:2009
单位:Research Institute of Information Technology (RIIT), Tsinghua University, Beijing, China. 清华大学信息技术研究院(RIIT)。
Tsinghua National Lab for Information Science and Technology (TNList), Beijing China. 中国北京清华大学信息科学与技术国家实验室。
# 1. 摘要
在过去的十年中,数据包分类问题被广泛研究,以加速网络应用,如访问控制、流量工程和入侵检测。在我们的研究中,我们发现虽然近年来提出了大量的数据包分类算法,但遗憾的是其中大部分都停滞在数学分析或软件模拟阶段,很少有作为通用解决方案在商业产品中实现。为了填补理论与实践之间的空白,在本文中,我们提出了一种名为 HyperSplit 的新型数据包分类算法。与著名的HiCuts和HSM算法相比,HyperSplit在分类速度、内存使用和预处理时间方面取得了卓越的性能。 在我们的测试中,提出的算法的实用性体现在两个事实上。HyperSplit是唯一能够成功处理所有规则集的算法;HyperSplit也是唯一在Octeon3860多核平台上用64字节以太网数据包对10K ACL规则进行测试时达到6Gbps以上吞吐量的算法。
seek novel and efficient packet classification solutions due to the following reasons:
- 网络带宽的持续增长 需要新的数据包分类解决方案来处理指数级增长的流量 边缘和核心设备上的流量。
- 不断增加的网络应用的复杂性。
- 网络系统的技术革新。 新的数据包分类解决方案必须很好地适用于先进的硬件和软件技术来打破瓶颈
回顾现有的工作,我们发现,虽然有大量的数据包分类算法 我们发现,尽管近年来有大量的数据包分类算法被提出来几年来提出了大量的数据包分类算法,但大多数都停留在数学分析和/或软件模拟阶段。而其中很少有而在商业产品中作为一种通用的解决方案。现有工作中理论与实践之间的差距可以根据不同的研究动机来总结动机。
# 2. 主要贡献
在本文中,我们 提出了一种新的数据包分类算法,并在新一代多核网络处理器上对其进行了评估。本文的主要本文的贡献包括:
- 问题分析 (
Problem Analysis) - 提出一种新型的算法 (
A Novel Algorithm) 在本文中,我们提出了一种新型的数据包分类算法,它结合了现有算法的优点:基于规则的空间分解和局部优化的递归。 提出的HyperSplit算法保证了明确的最坏情况下的分类速度,并利用规则集的数据冗余来减少内存的使用。数据结构也是精心设计的,以实现高效的存储和快速的访问。
原文
In this paper, we proposed a novel packet classification algorithm by combining the advantages of existing algorithms: rule-based space decomposition and local-optimized recursion. The proposed HyperSplit algorithm guarantees explicit worst-case classification speed and explores the data redundancy in rule sets to reduce memory usage. The data structure of HyperSplit is also carefully designed for efficient storage and fast access.
- 性能评估 (
Performance evaluation)
提出的HyperSplit算法以及HiCuts和HSM在Cavium Octeon3860多MIPScore平台上实现并进行了评估。实验结果表明:在各种现实生活中的规则集上,HyperSplit在 分类速度、内存使用和预处理 方面取得了比HiCuts和HSM更好的整体表现
本文的以下章节组织如下。第二节介绍了数据包分类问题,并分析了其理论和实际的复杂性;第三节比较了两种有代表性的数据包分类算法,总结了现有工作的通用解决方案;第四节描述了提出的算法HyperSplit,并在第五节进行了评估;在第六节,陈述了结论。
The object of packet classification is to classify packets by applying a set of rules to the header fields of a packet.
# 3. 现有工作
由于复杂度极高,在单一步骤中解决数据包分类问题是不可行的。大多数现有的算法采用分而治之 (divide-and-conquer) 的解决方案。搜索空间被分解为子空间,每个子空间都与一个规则子集相关联。通过递归地应用这种空间分解,原始问题被划分为一系列复杂度较低的子问题。
一般来说,现有的采用分而治之策略的算法都要经过以下两个步骤:
Space DecompositionRecursion Scheme递归方案
# 4. 现有算法
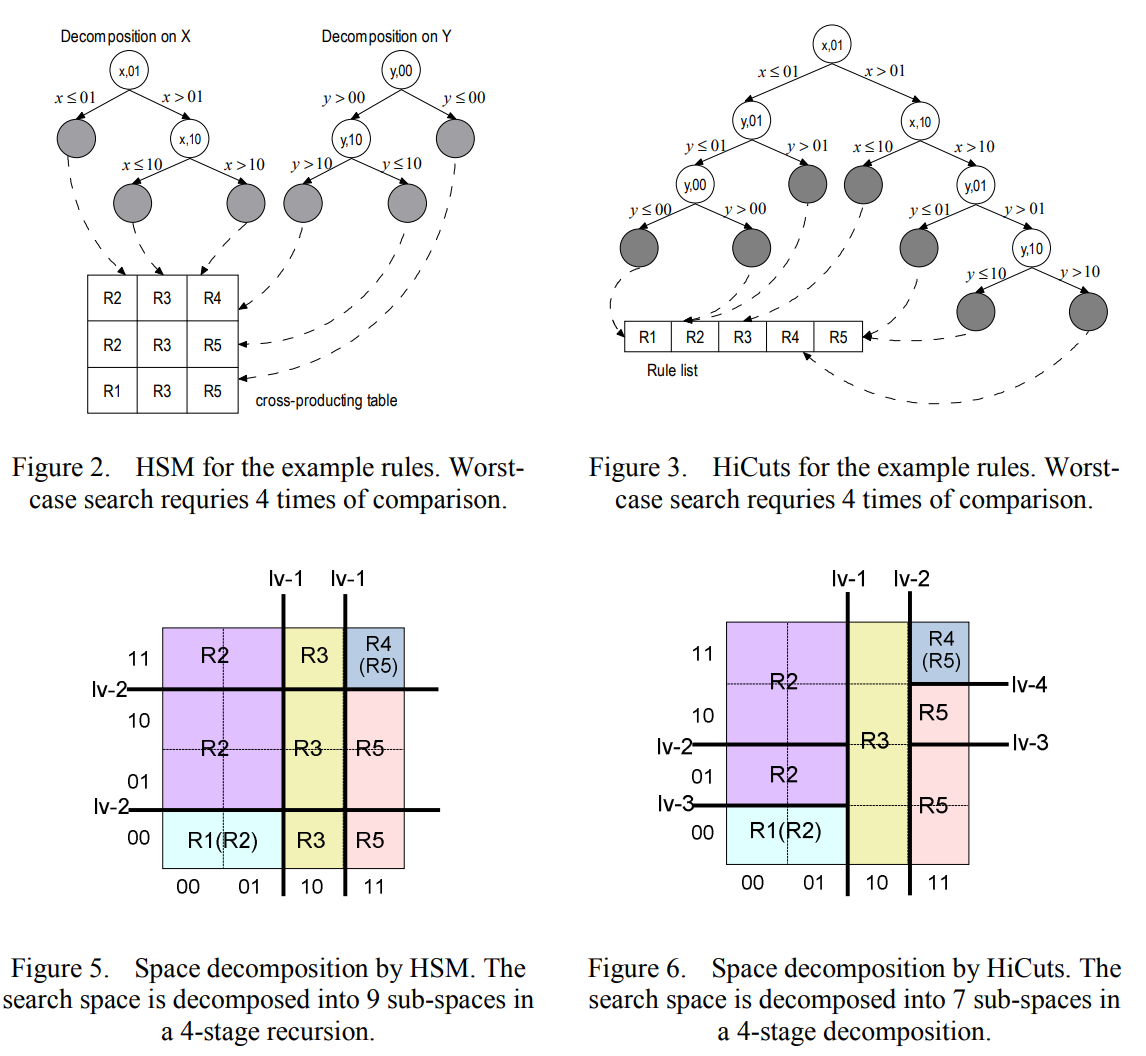
# 4.1 HSM (Hierarchical Space Mapping)
按照特定的顺序在搜索空间
S的F域进行 分层空间映射利用
rule-based space decomposition策略。例如,Sis decomposed along a predetermined fieldfby all the unique end-points of rule projections onf. (不理解这段)递归方案是
impartially-treated的。
原文
sub-spaces obtained in the previous stage are further decomposed by all rules and along all other fields in a predetermined order. In the final stage, all sub-spaces are fully covered by the associated set of rules, in which the one with the highest priority is the best match. (不理解这段)
# 4.2 HiCuts (Hierarchical Intelligent Cuttings)
- 采用
equal-sized空间分割策略:在每个维度上进行等尺寸分割,搜索空间S被分解成一系列等尺寸的子空间 - 不断 重复等尺寸分割 这个策略,对每个阶段的空间分割采用
local-optimized方案
原文
the field to apply decomposition depends on the rules associated with the current search space S instead of the whole rule set. HiCuts recursion terminates when the number of rules associated with current search space is less than a predetermined value. The final results are obtained by linear search. (不理解和HSM的区别)
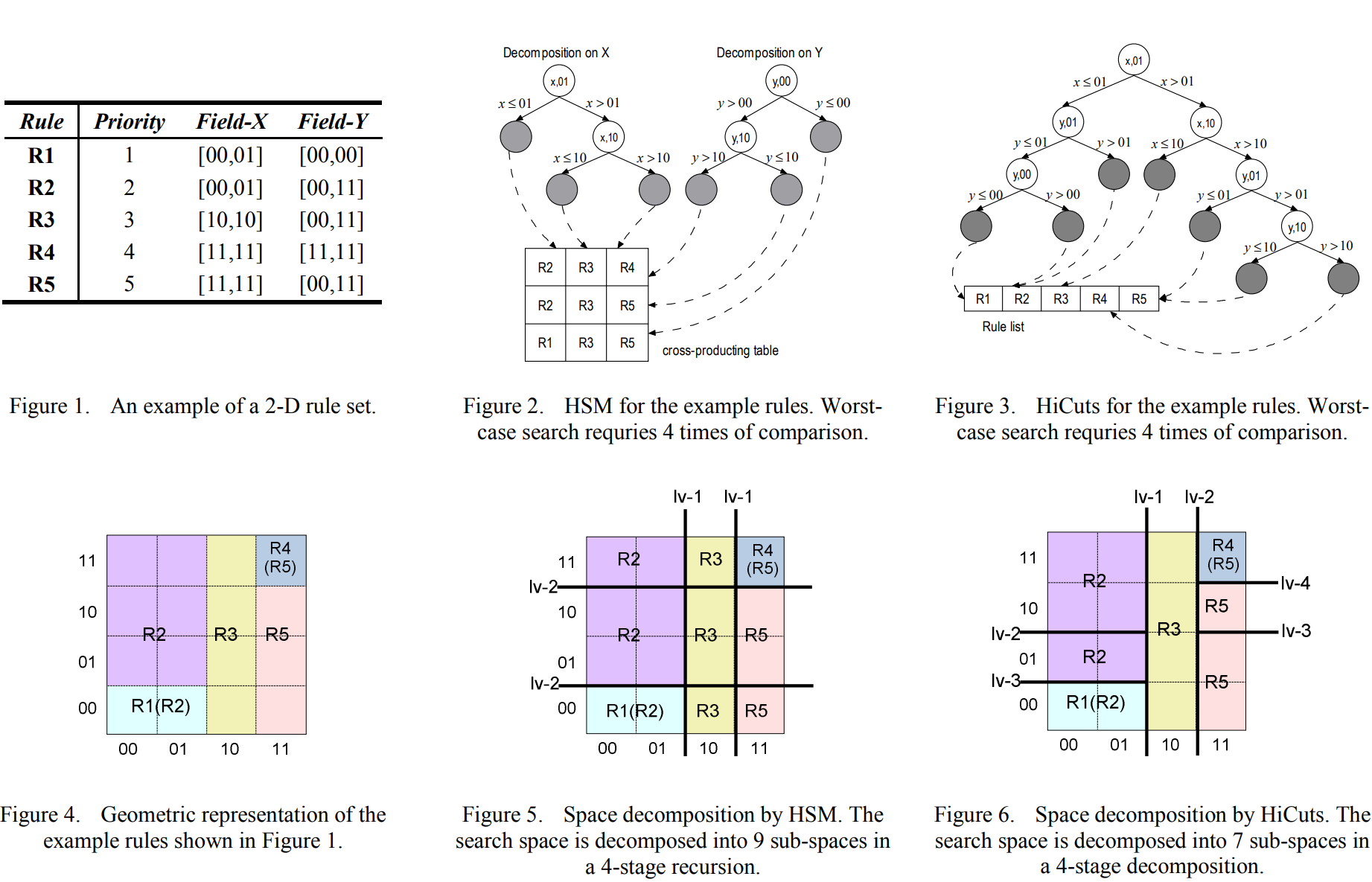
# 5. 新算法的提出
# 5.1 分析
根据对现有工作的分析,新型数据包的分类算法应满足以下设计目标:
明确的搜索速度
(Explicit search speed)。由于分类率是往往是现实生活中最重要的性能指标,所以搜索速度应该在最坏的情况下有一个约束,以保证系统的整体性能。适度的内存存储
Modest memory storage。首先,最重要的是,内存存储不能超过整个系统的内存大小。 此外,适度的内存存储使我们能够使用快速的内存技术,如片上SRAM,使内存访问更有效率。使内存访问更有效率
根据上面的分析,由于确定性的时间复杂度,HSM很好地满足了第一个要求,但是它遭受大量的存储器使用。相比之下,尽管HiCuts没有明确的搜索最坏情况界限,但由于局部优化的递归方案,它的存储效率很高。
| HSM | HiCuts | |
|---|---|---|
| 速度 | 搜索速度快 | 对搜索速度没有约束 |
| 内存 | 占用内存大 | 存储效率高 |
为了扬长避短,直接的想法是结合以下 两种策略 :
- 对每个字段进行基于规则的空间分解,以实现确定性的最坏情况搜索界限。
- 采用局部优化递归方案,来避免不必要的内存存储。
然而,这两种思想的结合给新算法的设计带来了一系列挑战性的 问题 :
对于搜索速度 : 无论处理哪种规则,如何确定显式的最坏情况搜索界限?
对于内存存储 : 为了将字段
(field)分解成
这些问题的答案是我们工作的核心思想。 我们的解决方案是在每个递归阶段沿着优化的字段应用二元空间分解,然后:
- 最坏情况下的搜索时间是明确的:
- 内存存储效率高:二分搜索法每一级只需要一个端点进行比较,对于
5元组包分类,一个端点最多32位。
而且,使用二进制分解,减少了预处理时间: 因为每个分区后只生成两个子空间,所以不需要空间聚合。结果,避免了HSM和HiCuts的预处理中最耗时的部分。
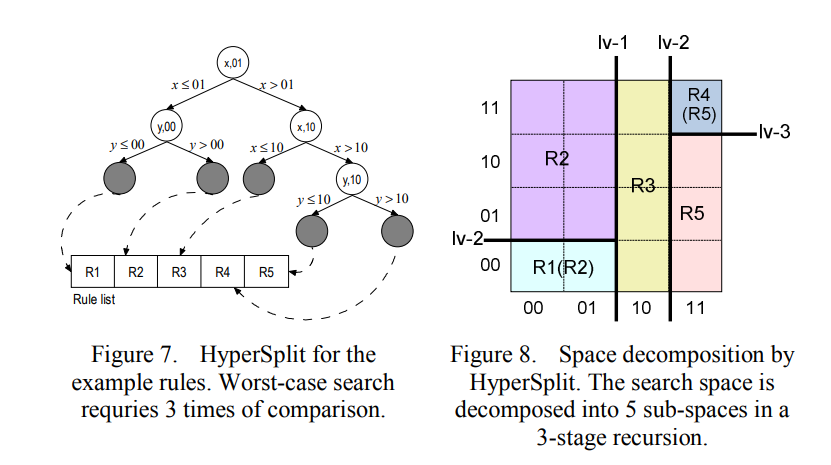
# 5.2 HyperSplit
点击查看
所提出的算法HyperSplit使用以下策略构建分类数据结构
空间分解
- 输入:搜索空间
(search space)(field)(rules) - 投影
- 超平面分割空间(二维中超平面就是一条直线,三维中超平面是一个平面,多维进行分割就是用超平面)
- 输入:搜索空间


- 递归方案
- name: 数据包分类
desc: 手写笔记:HyperSplit
link: https://maifile.cn/dec/a56182551994@doc
bgColor: '#DFEEE7'
textColor: '#242A38'
# 问题
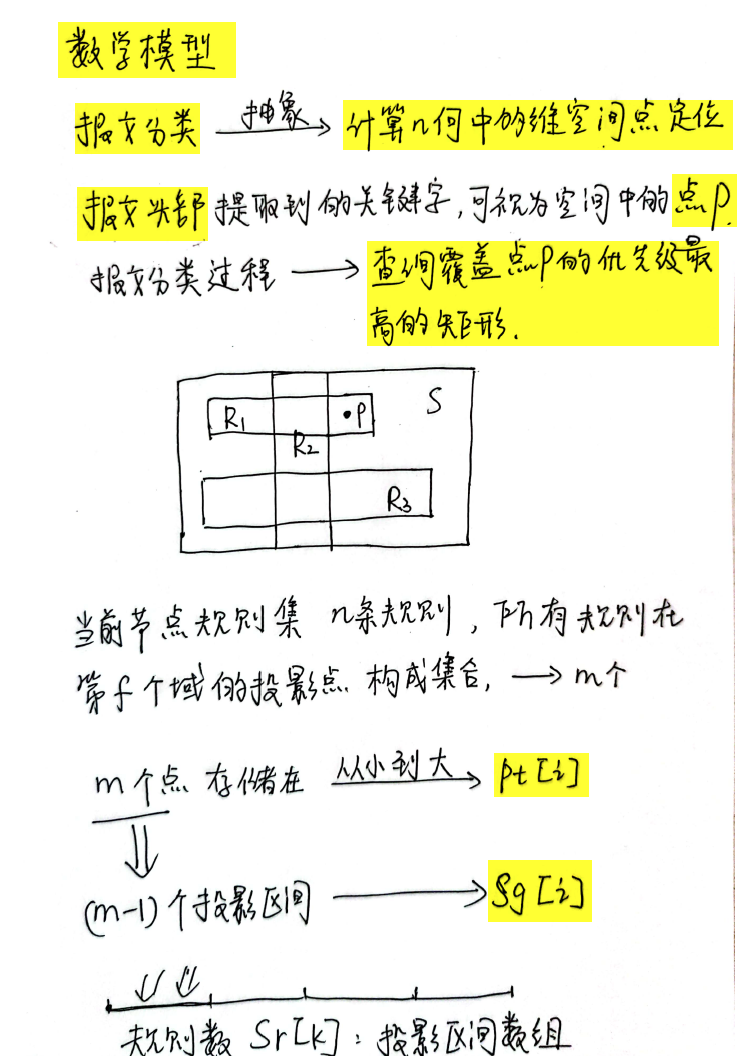
问题 1
域(字段)、规则、空间这些概念太抽象
字段 ,如 <源IP地址、目的IP地址、源端口、目的端口、协议> 这些分别都是一个字段,一共有
5个字段,那么就是有5个维度、5个域。空间 :每一个规则都对应着一块空间,空间是
5维的,空间大小就是规则的5个字段所构成的范围。每一个维度可能代表源IP地址、目的IP地址......,可能是一个值,也可能是一个范围,每一个维度上的取值范围所构成的空间集合就是 某个规则R1对应的空间。- 有两个字段的,对应的空间就是一个平面
问题 2
HSM、HiCuts、HyperSplit决策树
问题 3
如何选择 end-point 来分割?
# 基于决策树的报文分类算法分析
决策树算法主要思路是构建一棵或多棵决策树,叶子结点包含一条规则或一个规则子集,根据从报文头部提取到的关键字信息,横穿决策树,找到所属叶子结点,然后线性查找叶子结点存储的规则子集。这类算法突出的特点在于决策树经映射可以用 FPGA 多级深度流水线实现,速度快、吞吐率极高
基于决策树的报文分类算法从计算几何的角度看待报文分类问题。
- 每条规则 → 多维空间的超长方体
- 每个报文头部 → 多维空间的一个点
决策树构建算法采用递归的方式将当前空间切分为更小的子空间,每一步可以沿一个维度切分,也可以沿多个维度切分,最终形成的每个子空间包含有少量的相互交叠的超长方体(即规则), 采用线性查找的方法就可以用较小的代价找到包含目标点(报文)的最佳匹配。
报文匹配查找时,根据提取到的报文头部相关域的数值,算法逐步沿着切分序列定位到目标子空间(决策树的一个叶节点),线性查找即可得到最佳匹配规则,完成分类过程。
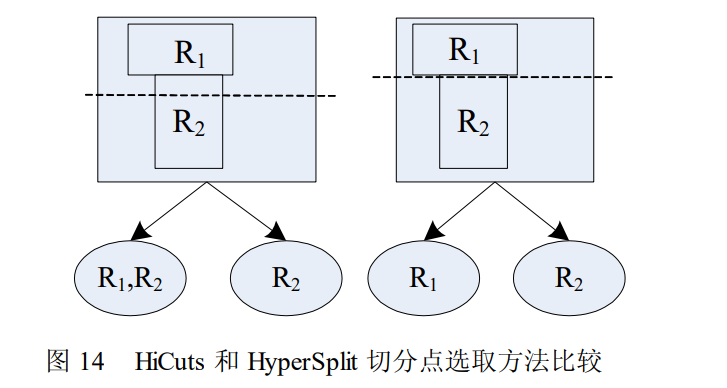
# HiCuts 算法
点击查看
HiCuts每一步通过分离性判别函数(discrimination function)选取可分性最好的维度,在该维度上对当前搜索空间进行均
匀切分,切分的次数为 2 的幂次
- 决策树的节点数量和节点内包含的规则数量决定了算法最终的内存使用量
- 决策树的深度和叶节点包含的最大规则数量决定了算法对每个报文的最大处理时延
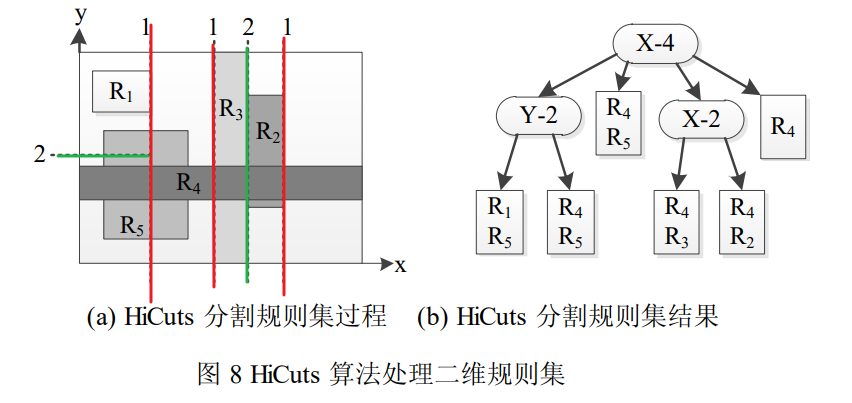
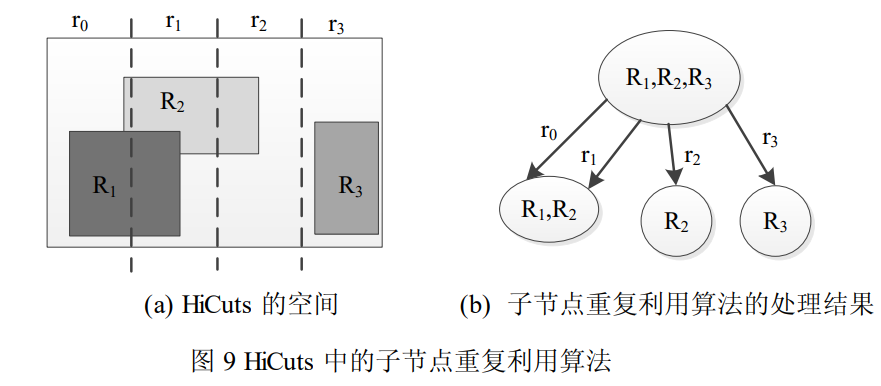
- 子节点重复利用
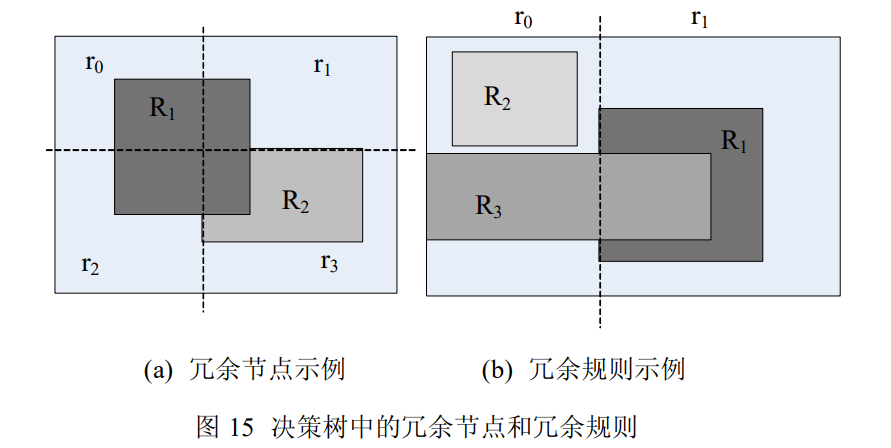
经过一系列沿维度的空间切分后,很多子节点包含的规则集同。在这种情况下,HiCuts 避免了分别创建那些包含有相同规则集的子节点,而改用子节点共享的方法处理之。具体说来,包含了两层意思:(1) 当前节点必须存储所有指向潜在子节点的指针;(2) 所有子节点必须存储有明确的空间边界。
子空间 r0 和 r1 包含有相同的规则集 {R1,R2} ,采取子节点重复利用的方法,只需创建一个子节点,然后让当前节点中指向原先各自子节点的指针指向共享子节点。
 (opens new window)
(opens new window)
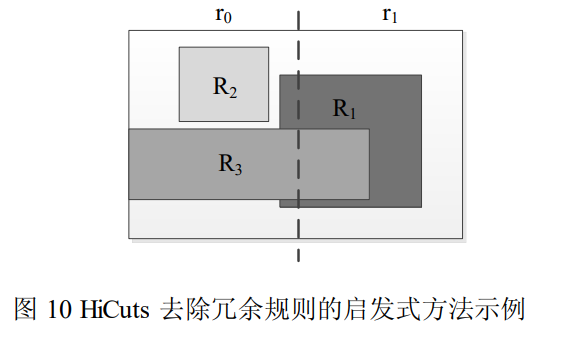
- 冗余去除
经过一系列沿维度的空间切分后,子空间中相当数量的规则被优先级更高的规则完全覆盖,则被完全覆盖的规则永远不可能被匹配,形成冗余规则。为降低算法的内存使用量,必须去除决策树中的冗余规则。
在子空间 r1 中,规则 R3 被规则 R1 完全覆盖,且规则 R1 的优先级高于 R3,则 R3 成为子空间 r1 中的冗余规则,必须去除。但是在子空间 r0 中,R1 和 R3 只是部分重叠,因此 r0 中没有冗余规则。
# HyperCuts 算法
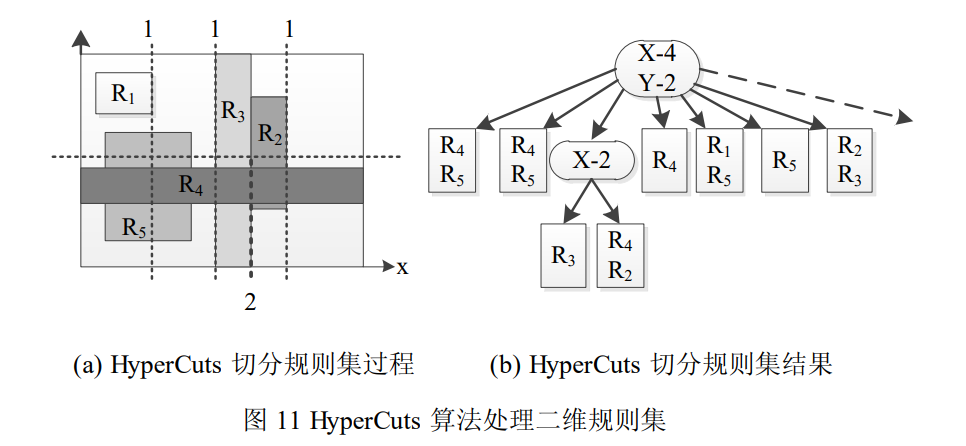
点击查看
HyperCuts 算法在 HiCuts 算法的基础上进行了改进。HiCuts 每次选取一个维度均匀切分,HyperCuts 为降低决策树深度以减少规则查询时间,每次选取多个维度均匀切分,两种算法均采用启发式方法保证切分维度和切分点的选取是最优的
区间压缩
 (opens new window)
(opens new window)共有规则上移
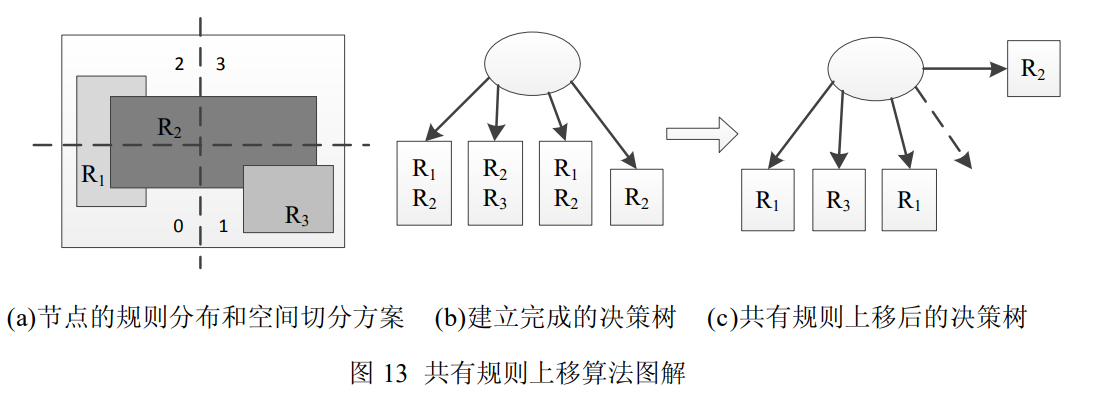
# HyperSplit 算法
HyperSplit 算法是近年提出的一种实用的报文分类算法。不同于 HiCuts 和 HyperCuts 的均匀切分,它每步将规则在特定维度上的某个投影点作为切分点,因此是一种非均匀的空间二分算法,同时作者提出了在非均匀空间二分前提下切分维度选取的启发式方法。文献中的仿真结果表明,该算法是目前基于决策树的报文分类算法中内存使用量最小的算法。
# 相关知识补充
网络数据包分类是指路由器通过提取到达数据包的头部字段信息,再与路由器中的规则集进行匹配,然后执行匹配规则中定义的动作,即转发数据包到相应网口或者丢弃数据包等
当且仅当报文头部

# 好的句式
Packet classification is an enabling function for a variety of Internet applications including quality of service, security, monitoring, and multimedia communications. In order to classify a packet as belonging to a particular flow or set of flows, network nodes must perform a search over a set of filters using multiple fields of the packet as the search key. In general, there have been two major threads of research addressing packet classification, algorithmic and architectural. A few pioneering groups of researchers posed the problem, provided complexity bounds, and offered a collection of algorithmic solutions